[Thanks to Drake Thomas and Mike Winston for discussion.]
In third grade math class, my teacher Ms. Potter taught my class about the mean, median, and mode of a list of numbers. What united these numbers, Ms. Potter told us, was that they were measures of central tendency: numbers that represented, in some sense, the “middle” of the data.
I remember being dissatisfied with the mode being labeled a measure of central tendency. After all, it’s really easy to construct an example (1, 1, 2, 3, 4, …, 100) where the mode is nowhere close to the middle of the data. I don’t remember whether I voiced this objection to Ms. Potter, but my mental model of her would have responded with “Well, for typical lists of numbers that occur in real life, the mode generally is close to the middle” — or anyway, that’s the half-satisfying explanation I ended up giving myself.
But as pointed out by Buck Shlegeris, there is some really cool math connecting the mean, median, and mode, and the mode really does deserve its place as a measure of central tendency.
To re-explain Buck’s post: the median 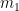
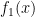

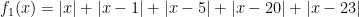


(For an even number of elements, there is a tie for this minimum value among all numbers in between the two middle numbers, inclusive — so for the list 0, 1, 5, 8, 20, 23, every number in the interval ![[5, 8]](https://s0.wp.com/latex.php?latex=%5B5%2C+8%5D&bg=ffffff&fg=000000&s=0&c=20201002)
What about the mean? It turns out that the mean 
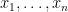
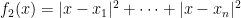
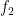

And the mode? It turns out that’s just the number 

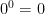
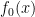

And so if you’re mathematically inclined, you’re probably thinking, why stop there? We can define 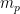
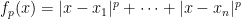

At this point in the post, if you’re so inclined, it would be a good time to pause and see what you can discover about p-medians for general values of 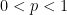
It turns out that when

Here’s a plot of 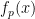
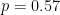
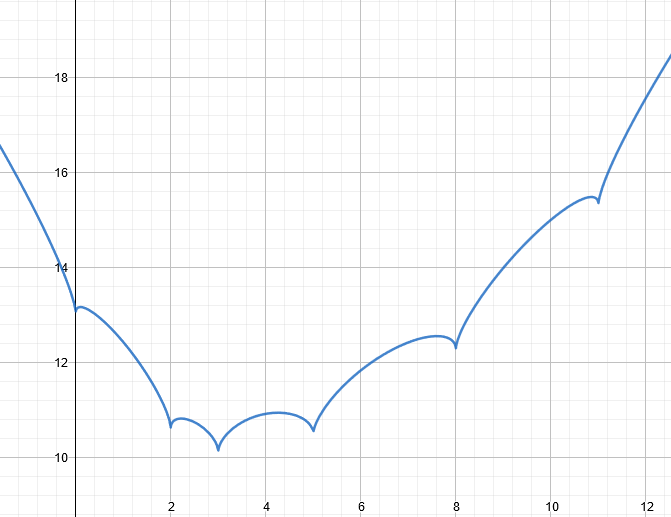
We have

which is negative on each interval 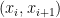
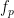

So, given a list, which values are the p-median for some 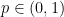
0, 1, 1, 3, 4, 5, 50, 60, 61, 62, 70, 80, 90.
The p-median changes with p as follows:
- For
, the p-median is 50 (the median).
- For
, the p-median is 60.
- For
, the p-median is 61.
- For
, the p-median is 4.
- For
, the p-median is 3.
- For
, the p-median is 1.
The key intuition here is that for p close to 1, the p-median is near the middle of the list. As p gets smaller, being close to other elements matters more and more. This makes sense, because the 0-median is the mode, i.e. the number in the list with the greatest number of other list members that are exactly equal to it.
In this example, several elements of the list are the p-median for some p; but it is no coincidence that 0 and 90 never are. Assuming that the smallest and largest elements of the list each appear only once, they can never be the p-median. To see that, take the smallest and second-smallest elements, and consider the distances from them to every other element in the list. In our earlier example [0, 1, 5, 20, 23], the distance from 0 to the other elements is 1, 5, 20, 23, and the distance from 1 to the other elements is 1, 4, 19, 22. Comparing these distances one by one, we find that the distances from the second-smallest elements are always smaller than the corresponding distances from the smallest element, meaning that for any p, the sum of distance raised to the p-th power is smaller for the second-smallest element than the smallest. This reasoning also works for the largest and second-largest elements.
Is it possible to have a list of numbers of arbitrary length such that every element besides the two extreme ones serves as the p-median for some
Another question is: what’s the behavior of the p-median in the limit as p approaches 0? This is a cool question because it’s a natural way to define the mode of a list of distinct numbers. Recall that for 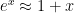
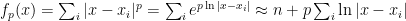
for p close to 0, which means that the limiting value of
This leads us to an interesting connection of the p-median with the generalized mean. The p-power mean of a list of nonnegative numbers 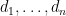

Familiar cases are the arithmetic mean (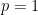
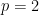

The median (1-median) of a list of numbers is the number that minimizes the arithmetic mean (1-power mean) of the distances to the numbers in the list. The (arithmetic) mean (2-median) is the number that minimizes the quadratic mean (2-power mean) of the distances. The mode (0-median) minimizes the geometric mean (0-power mean) of the distances.2 More generally, perhaps a more natural definition of the p-median is the number that minimizes the p-power mean of distances to the numbers in the list.
Indeed, this is the definition that extends naturally to negative values of p, allowing us to define the -1-median as the number maximizing the sum of the reciprocals of the distances to all other numbers.
What about the limit as p approaches infinity? As p grows to infinity, the p-median becomes the average of the smallest and largest numbers in the list, because large distances are punished more and more relative to smaller ones.
And as p approaches negative infinity? There, having small distances to one’s neighbors is increasingly rewarded, so the p-median becomes the number in the list with the smallest distance to its closest neighbor. (Well, there are two such numbers; it’s the one whose distance to its other neighbor is smaller.)
So as p varies, we observe some interesting behaviors:
- When p is really large, the p-median is the average of the two extreme elements.
- As p gets closer to 2, the p-median becomes more and more equally influenced by each element of the list (in the sense that perturbing each element has the same effect on the p-median).
- As p further decreases to 1, the p-median approaches the middle value(s) of the list.
- As p decreases toward and beyond 0, the p-median tends toward elements that are close to other elements. In the limit as p becomes very negative, being close to your nearest neighbor is the only thing that matters.
I see the p-median, for 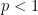
100, 320, 320, 325, 330, 400 (median), 500, 600, 700, 1000, 1500
But something interesting is going on in the data: four of the numbers are really close together. A reasonable conclusion to draw from this data set is that four of the people you asked know the approximate answer, while seven are just guessing. If I knew nothing about the population of the United States and saw these answers, I’d guess that the population is 325 million even though the median answer was 400 million (and the mean is even larger).
This is what the p-median accomplishes for 

So here’s a bold conjecture: in practice, when estimating quantities in the real world from asking around, using the 0.8-median is better than using the median.
I’m very uncertain in this conjecture –I’m not sure I’d bet on it at even odds (though it’s close) — but I find it very plausible and it would be very interesting if it were true.
1. Yes, it is possible! One example is 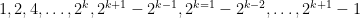

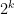
2. Well technically that’s 0 for every number in the list, but the limit of the p-median as you push p to zero is the number minimizing the geometric mean of the distances to all other numbers.↩

Someone in a Reddit discussion of this post mentioned the concept “M-estimator”. The Wikipedia article on M-estimators is too dense for me to fully understand, but it does seem like they are related.
LikeLike
Thanks for the pointer! I wasn’t able to understand the article at first glance but will take a look again later 🙂
LikeLike
I thought this was very interesting. What about data in more than one dimension? What are the best measures of central tendency for 2-D data, or 1000-D data?
LikeLike
Good question (which I won’t answer)! As you point out, p-medians generalize to n dimensions; see e.g. https://en.wikipedia.org/wiki/Geometric_median. I would be quite interested to see if anyone has any cool observations about p-medians in higher dimensions!
Another interesting thing to think about is p-medians for continuous distributions, rather than finite sets of numbers/points. It would be cool to draw some (asymmetric) distribution and then animate where the p-median is as p changes. (I don’t think I’m up to this task though.)
LikeLike
Great work! I was actually thinking about this relationship between mean (minimizing squares) and median (minimizing first powers) a few months ago, but I never realized how you could also think of mode this way. It’s interesting how for negative p, the p-median is forced to be one of the numbers of the original list because it needs to be infinity plus some real value (and choosing a point that isn’t among the list would only have a finite value). You avoided dealing with infinity stuff by defining it to be one of the numbers and only looking at distances to other points, but it results to the same thing.
I’m also wondering if you have an intuitive way to see that the p-median has a unique value? Is it ever the case that there are two distinct values that, say, minimize the sum of fifth powers of distances to the numbers? I’m discounting special cases like mode, which can be a whole interval.
LikeLike
Yeah so I think that for any p > 1 this is true. That’s because for any ,
, 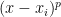 is strictly convex, which means that
is strictly convex, which means that  is strictly convex, and a strictly convex function can only have one minimum.
is strictly convex, and a strictly convex function can only have one minimum.
LikeLiked by 1 person